很多人对降AI工具的理解停留在「把AI写的文字改得不像AI写的」,但换了几款工具发现效果差距很大,原因就在于不同工具的技术路径完全不同。
要理解比话降AI的Pallas引擎,先要搞清楚知网在检测什么。
知网AIGC检测:2026年升级了什么
2026年知网完成了一次大升级,从单一检测模型换成了多模型融合架构,同时使用多种检测方法并综合判断:
- 统计特征分析:分析文本的困惑度(Perplexity)、突发度(Burstiness)、词频分布等统计指标
- 深度语义分析:用大语言模型理解文本的语义连贯性和逻辑结构
- 风格指纹识别:对比分析文本风格与已知AI模型输出的相似度
- 段落级精细检测:不只给出全文AI率,对每个段落独立评估
关键变化:这次升级覆盖了DeepSeek、文心一言、Kimi、通义千问等国产大模型的输出特征,比2025年准确率提高约10%。
换句话说:换个冷门模型写不再能绕过检测。

同义词替换为什么越来越不管用
传统的「降AI」方法主要是同义词替换——把AI常用的词换成不那么常见的表达。这个思路的问题在于:
AI生成文本的特征不只体现在词选择上,还体现在统计层面。
人类写作有一个特点叫「突发度(Burstiness)」——同一个词在段落里的出现是不均匀的,有时密集出现,有时消失很久。AI生成文本的词频分布非常均匀,这是统计特征,不是换几个词能改掉的。
同义词替换后,统计特征依然保留,检测模型依然能识别出来。
Pallas引擎的技术路径
比话降AI 的Pallas引擎(Pallas NeuroClean 2.0)的核心逻辑是从统计特征层面重构文本,而不是停留在词汇替换层面。
具体来说,引擎会:
- 分析当前文本的AI统计特征分布
- 重构句子的句式模式和连接结构
- 引入自然语言的「不均匀性」
- 保留核心内容和专业术语不变
结果是:处理后的文本从统计模式上更接近人类写作,而不只是词汇层面的替换。

这也是为什么比话的处理结果通常学术性保留比较好——引擎针对的是统计特征,不是语义内容,所以专业术语和学术表达基本不会被改动。
对比:同义词替换 vs 统计特征重构
| 维度 | 同义词替换 | 统计特征重构(Pallas) |
|---|---|---|
| 词汇层面 | 会改动 | 改动较少 |
| 句式层面 | 基本不变 | 重构句式模式 |
| 统计特征 | 保留AI特征 | 消除AI统计特征 |
| 检测通过率 | 不稳定 | 达标率99% |
| 学术表达保留 | 可能被误改 | 专业术语基本不动 |
为什么不能降到0%?
一个常见的问题:为什么不把AI率降到0%,而是要保留一定比例?
原因有两个:
- 检测有±3%的波动:今天测10%,明天测可能是7%或13%,保留一定余量更安全
- 降到0%可能被怀疑:完全没有AI特征的学术论文也不自然,部分学校会进一步审查
比话的推荐目标是知网AI率降到10%-15%,不追求0%。
实测数据
同一篇论文,知网原始AI率58%,经Pallas引擎处理后:
- 降至11%(知网实测)
- 文本读起来仍是学术风格
- 专业术语和数据完整保留
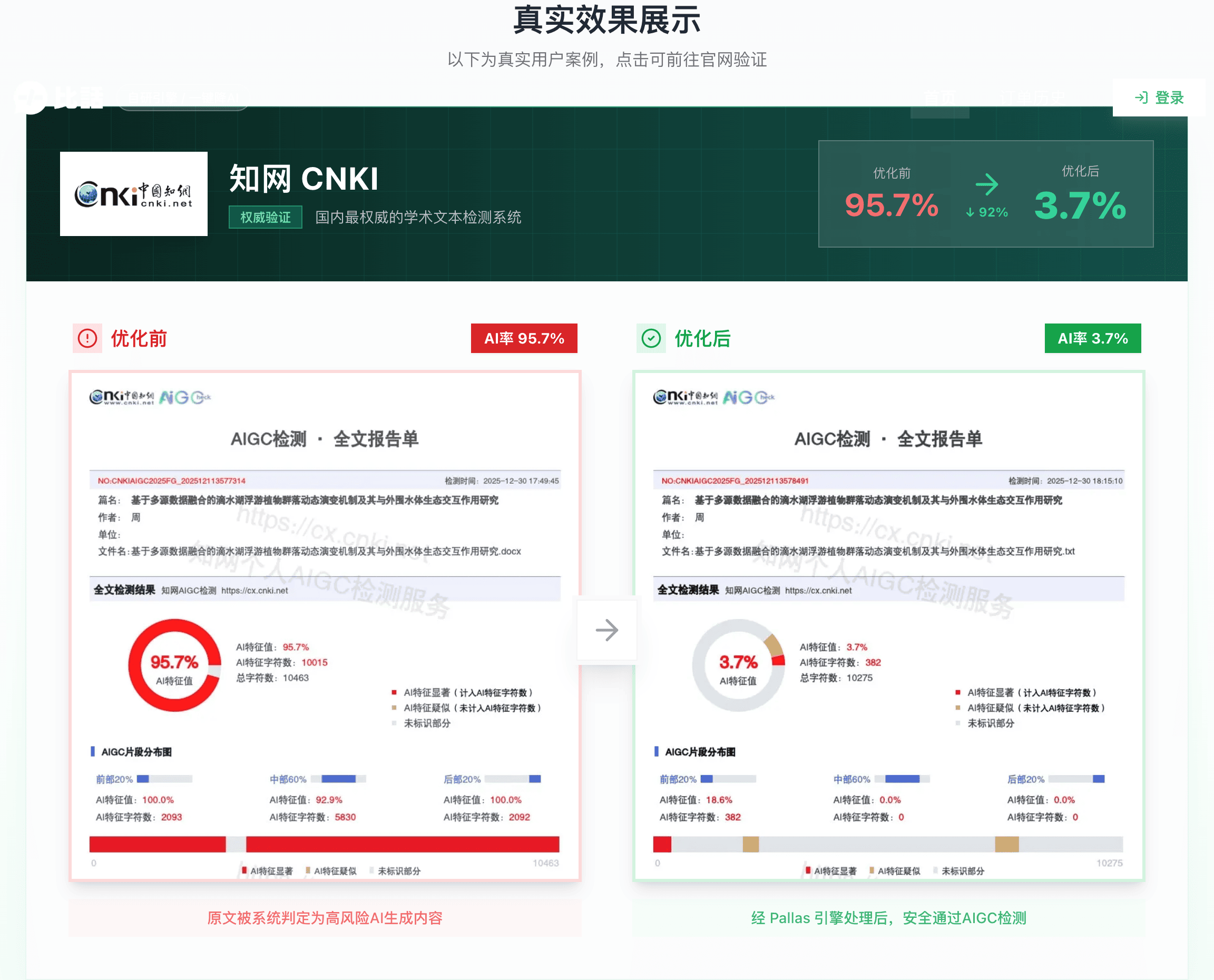
这个数字(58%→11%)不是广告语,而是比话退款政策的底气所在:知网AI率降不到15%以下,全额退款。承诺能写进退款条款里,说明这是真实的技术能力。